

AI Mycelium: Why ‘Tiny’ Is Twisting the AI Economy
The AI industry has been playing the wrong game. The answer isn’t bigger. It’s smaller, interconnected, and specialised.

While tech giants race to build ever-larger models (trillion-parameter behemoths requiring warehouse-sized data centers) nature has already solved the intelligence problem.
Welcome to the Mycelium Revolution.
Samsung just proved what mycologists have known for decades: distributed networks of specialised nodes beat centralised giants every time. Their 7-million parameter Tiny Recursive Model outperforms systems 10,000 times larger on complex reasoning tasks. Not by a small margin. Categorically.
The industry response? Keep building bigger.
This is the technological equivalent of responding to traffic congestion by building wider highways. It’s a fundamental misunderstanding of the problem.
The Cathedral vs. The Forest Floor
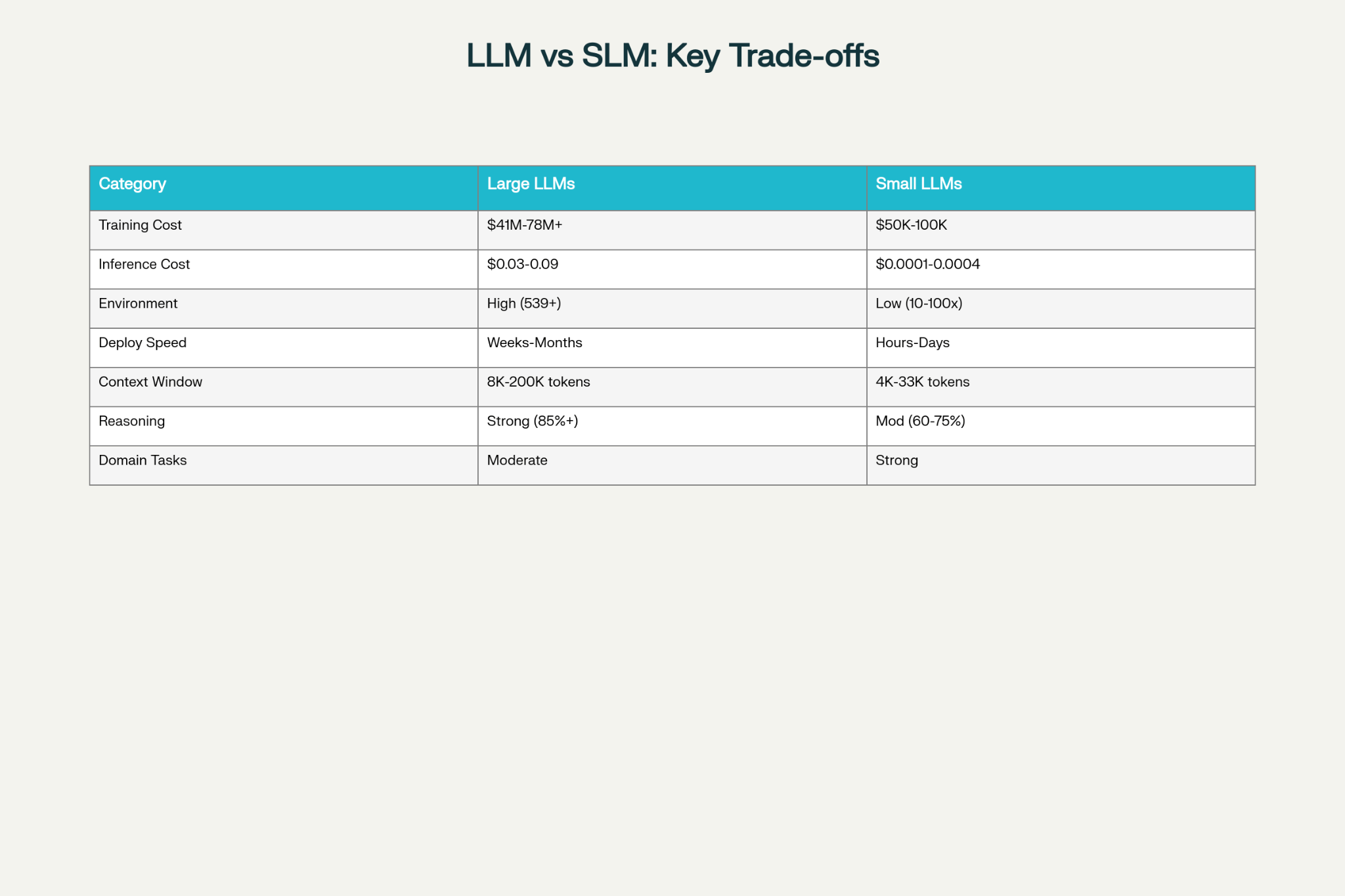
Here’s what the AI giants are building: cathedrals. Massive, impressive, resource-intensive monuments to computational power. GPT-4 cost between $41 million and $78 million to train. These models consume electricity equivalent to small cities and generate carbon emissions that would make a coal plant blush.
Here’s what actually works in nature: mycelium networks.
Beneath every forest floor lies an intelligence network that makes our most sophisticated AI look primitive. Mycelium (the underground fungal networks that connect trees) operates on a principle the AI industry hasn’t grasped: distributed specialisation beats centralised scale.
A single mycelium network can span thousands of acres. It doesn’t process everything in one massive hub. Instead, it routes nutrients, chemical signals, and information through countless specialised nodes, each optimised for specific functions. Trees communicate stress signals. Nutrients flow from areas of abundance to areas of need. The network adapts in real-time without any central controller.
This isn’t just a pretty metaphor. It’s an architectural blueprint the AI industry is finally starting to discover.
The Uncomfortable Math Nobody Wants to Talk About
Let’s talk numbers, because the AI industry certainly doesn’t want to.
Training GPT-3 consumed approximately 1,287,000 kWh of electricity. Llama 2 generated 539 tonnes of CO2 equivalent the lifetime emissions of 113 cars. And these models keep getting bigger while release cycles keep getting shorter.
Here’s the part that should make you angry: 70-90% of AI’s energy consumption happens during inference, not training.
Meta reports 70% of its AI power consumption goes to inference. Google says 60%. AWS indicates 80-90%. That means every time you query a large model, you’re burning energy at scale. Multiply that by millions of daily queries across enterprises worldwide, and you have an environmental disaster hiding behind the word “innovation.”
Meanwhile, quantisation and distillation techniques can reduce carbon emissions by 63-65% compared to full models. A distilled 600M parameter model achieves 71-78% faster inference with minimal performance loss.
The technology to reduce AI’s environmental catastrophe exists. The industry just isn’t using it because “bigger” makes better headlines than “efficient.”
225x: The Number That Should End This Debate
The cost comparison is so stark it borders on absurd.
GPT-4 charges $0.03 per 1,000 input tokens and $0.06 per 1,000 output tokens, totalling $0.09 per request.
Mistral 7B costs $0.0001 per 1,000 input tokens and $0.0003 per 1,000 output tokens: $0.0004 per request.
That’s 225 times cheaper for the small model.
Run those numbers at enterprise scale. A company making 100,000 API calls daily would pay $9,000 per day for GPT-4 or $40 per day for Mistral 7B. That’s $3.2 million annually versus $14,600.
For on-premises deployment, the math gets even better.
Running local small models with $1,000 hardware investment amortised over three years works out to approximately $1 daily cost, compared to $20 per day for cloud-based API usage.
But here’s what the cost comparison misses: it’s not either/or. The real opportunity is building networks of specialised small models that collectively outperform any single large model at a fraction of the cost and environmental impact.
When Small Actually Beats Big
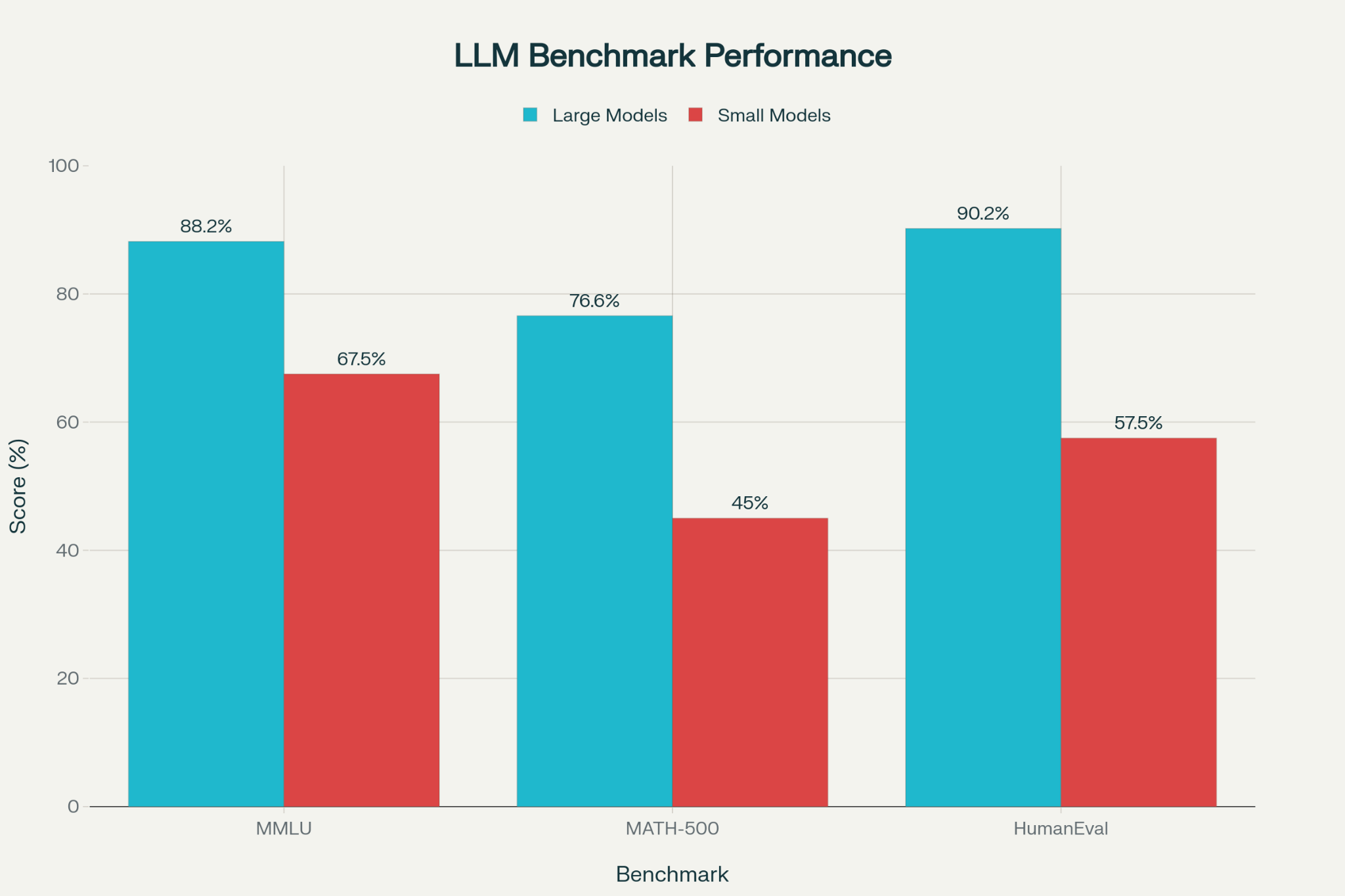
Microsoft research found something the large model vendors don’t advertise: small models like Phi-3 Mini and Mistral can actually outperform GPT-4 in specific application contexts, particularly when fine-tuned on domain-specific training data.
Read that again. Smaller models beating the flagship in real-world applications.
DeepSeek-R1-Distill-Qwen-7B achieves 92.8% accuracy on MATH-500 through specialised distillation. That’s a 7-billion parameter model competing with systems hundreds of times larger on complex mathematical reasoning.
The SLM-Bench comprehensive evaluation framework revealed that model size does not strongly correlate with performance across all dimensions. Mistral-7B maintained balanced performance across accuracy, computation, and consumption metrics - making it a stronger all-round candidate than models ten times its size.
This isn’t cherry-picking edge cases. This is the emerging pattern: specialised small models beat generalised large models on focused tasks.
The Mycelium Architecture: What AI Should Actually Look Like
Nature doesn’t build one massive tree to do everything. It builds ecosystems.
The mycelium network beneath a forest doesn’t try to be good at every possible function. Instead, it connects specialised nodes: one excellent at breaking down specific nutrients, another at signalling chemical alerts, another at storing carbon. The network’s intelligence emerges from the connections, not from any single massive node.
This is the architecture AI should be adopting.
Instead of one 175-billion parameter model trying to handle customer support, code generation, data analysis, and creative writing: build a network of specialised small models.
A 7B model fine-tuned on your customer support data. Another optimised for your specific codebase. Another trained on your industry’s analytical patterns.
Connect them through orchestration layers. Route queries to the appropriate specialist. Let them share context when needed. Build redundancy and resilience through distribution rather than replication.
This approach delivers several advantages simultaneously: lower costs, reduced environmental impact, better domain-specific performance, faster iteration cycles, and architectural resilience that no single large model can match.
When one node in a mycelium network dies, the network routes around it. When your favourite large model API goes down or the company decides to triple its prices you’re stuck.
The Resilience Dividend
There’s another advantage to the mycelium architecture that rarely gets discussed: resilience.
Centralised systems have centralised failure modes.
Every enterprise that built their AI strategy around a single large model vendor has a single point of failure for their entire AI capability. Pricing changes, API deprecation, service outages, data policy shifts: any of these can crater your AI operations overnight.
Distributed small model architectures route around these failures. If one model becomes unavailable or cost-prohibitive, you replace that node while the rest of the network continues operating. If a better specialised model emerges for one function, you swap it in without rebuilding everything.
This is how nature builds systems that last millions of years. It’s how AI architectures should be built to last beyond the next funding round.
The Emerging Pattern: Fit for Purpose
The industry is slowly recognising what should have been obvious from the start: “fit for purpose” outperforms raw capability.
Organisations deploying multiple applications increasingly use hybrid approaches: large models for R&D, prototyping, and novel reasoning tasks, then transition proven applications to fine-tuned small models for production deployment. This strategy combines large models’ versatility with small models’ efficiency.
But that’s still thinking in cathedral terms, i.e. using the big impressive thing, then scaling down.
The mycelium approach inverts this: start with small specialised models, connect them into intelligent networks, and only invoke large models when the network genuinely can’t handle the task. Most tasks don’t need trillion-parameter scale. They need focused capability, fast inference, and cost efficiency.
The 75% of IT leaders claiming they’ll be “more involved with AI this year” while running the same innovation theatre? They’re still building cathedrals.
They’re still measuring success by model size and vendor prestige rather than by business outcomes and operational efficiency.
The Environmental Reckoning
Here’s the part that should keep AI executives awake at night: the environmental reckoning is coming.
AI’s current trajectory is environmentally unsustainable. The industry’s carbon footprint is growing exponentially while the planet desperately needs it to shrink. Every new massive model release is celebrated as progress while its environmental cost is treated as an afterthought.
This will change. Regulatory pressure, ESG requirements, carbon pricing, and simple resource constraints will force the industry toward efficiency whether it wants to go or not.
The organisations building mycelium architectures now will have competitive advantages when that reckoning arrives.
The organisations still operating cathedral models will face expensive and disruptive rebuilds.
This isn’t environmentalism versus business outcomes. It’s recognising that efficiency is a feature, not a compromise. Smaller models are better for the planet and better for your operations. The alignment is perfect.
Building Your Mycelium Network
Stop asking “which large model should we use?” Start asking “what specialised capabilities do we need?”
Map your AI use cases by function. Customer support needs different capabilities than code generation needs different capabilities than data analysis. Identify the smallest model that can handle each function when fine-tuned on your domain-specific data.
Build orchestration infrastructure. This is your mycelium: the layer that routes requests, maintains context across models, and enables your specialists to work together. Tools like Airtable for workflow orchestration, n8n for automation, and MCP for model interoperability make this accessible without enterprise budgets.
Optimise ruthlessly. Use quantisation and distillation to compress models further. A distilled model with 71-78% faster inference and 63-65% lower emissions isn’t just environmentally better: it’s operationally better.
Monitor the ecosystem. Mycelium networks respond to changing conditions. Your AI network should too. Track performance by node. Identify bottlenecks and capability gaps. Upgrade individual specialists without rebuilding the whole system.
The Uncomfortable Question
So here’s what you need to ask yourself: When the environmental reckoning hits (when carbon pricing makes large model inference prohibitively expensive, when regulators start scrutinising AI’s energy consumption, when your customers start asking about your AI’s environmental footprint) what will your architecture look like?
A collection of expensive, resource-intensive cathedral models you’re locked into?
Or a resilient mycelium network of efficient specialists you can adapt as conditions change?
The mycelium revolution isn’t coming. It’s here. Samsung’s TRM proved the principle. The cost and environmental data prove the economics. The only question is whether you’ll build for the future or remain locked in the past.
Nature solved distributed intelligence billions of years before we started building neural networks. Maybe it’s time we paid attention.
The future of AI isn’t bigger.
It’s connected.